![]() Cassandraに入れたデータでMapReduceするサンプル(word count)を動かす。
Cassandraに入れたデータでMapReduceするサンプル(word count)を動かす。
環境
- CentOS 6.3
- Java 1.7.0_10
- Ant 1.8.4
- Cassandra 1.2.0-rc1
- Hadoop 1.1.1
構成
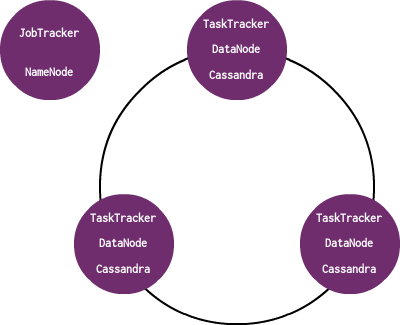 CassandraとTaskTrackerが同じノードにいるようにする
CassandraとTaskTrackerが同じノードにいるようにする
それぞれのインストール方法は割愛
手順
- HadoopがCassandraのライブラリを読み込むようにする
vi /etc/hadoop/hadoop-env.sh
# 末尾に追記
export HADOOP_CLASSPATH="/var/lib/cassandra/lib/*:$HADOOP_CLASSPATH"
- HadoopとCassandraを起動しておく
- Cassandraのビルド
git clone git://github.com/apache/cassandra.git
cd cassandra
ant
- word_countのビルド
cd examples/hadoop_word_count
vi ivy.xml
# バージョンを合わせる
<dependency org="org.apache.hadoop" name="hadoop-core" rev="1.1.1"/>
ant
- word_countの設定
vi bin/word_count
# 下記のように編集(mapred-site.xmlのパスは自分の環境に合わせる)
#$JAVA -Xmx1G -ea -cp $CLASSPATH WordCount output_reducer=$OUTPUT_REDUCER
$JAVA -Xmx1G -ea -cp $CLASSPATH WordCount -conf /etc/hadoop/mapred-site.xml output_reducer=$OUTPUT_REDUCER
- word_countの実行
bin/word_count_setup
bin/word_count
bin/word_count_counters
参考
- Hadoop Integration
- Hadoop Support DataStaxのエンタープライズ版だともっと簡単にやれるらしい